感谢光老师的无私奉献~
参考资料:
https://tech.meituan.com/2016/11/18/dianping-order-db-sharding.html 大众点评订单系统分库分表实践
https://developer.aliyun.com/article/770923 MySQL主从复制读写分离,看这篇就够了!
https://blog.csdn.net/q2524607033/article/details/133197100 MySQL主从复制与读写分离(附配置实例)
https://cloud.tencent.com/developer/article/2150908 mysql主从搭建、使用mycat实现主从读写分离[通俗易懂]
1. MySQL 引擎选择
https://developer.aliyun.com/article/1390031 MySQL ⽀持哪些存储引擎?默认使⽤哪个?MyISAM 和 InnoDB 引擎有什么区别,如何选择?
总结:
主库主要是写操作,应该选择 InnoDB 引擎;
从库主要是读操作,可以考虑选择 MyISAM 引擎,以提高读取性能。
1.1. 存储引擎概念
存储引擎就是存储数据、建立索引、更新/查询数据等技术的实现方式 。存储引擎是基于表的,而不是基于库的,所以存储引擎也可被称为表类型。我们可以在创建表的时候,来指定选择的存储引擎,如果没有指定将自动选择默认的存储引擎。
在 MySQL5.5后,存储引擎默认版本为InnoDB:show create table account;
1.2. 查询、指定、修改存储引擎
1.2.1. 查询当前数据库支持的存储引擎
show engines;

SHOW VARIABLES LIKE 'default_storage_engine';

1.2.2. 建表时指定存储引擎
ENGINE=InnoDB;
CREATE TABLE my_table (
id INT PRIMARY KEY,
name VARCHAR(100)
) ENGINE=InnoDB;1.2.3. 修改表、库的存储引擎
可以使用 ALTER TABLE 命令修改表的存储引擎:ALTER TABLE my_table ENGINE=MyISAM;
可以使用 ALTER DATABASE 命令修改库的存储引擎:ALTER DATABASE my_database DEFAULT ENGINE=InnoDB;
1.3. MySQL 存储引擎比较
MySQL 支持多种存储引擎,包括 InnoDB、MyISAM、MEMORY、CSV 等。默认情况下,MySQL 使用的存储引擎是 InnoDB。
MyISAM 和 InnoDB 是 MySQL 中最常用的两种存储引擎,它们有以下区别:
锁定方式不同:MyISAM 使用表级锁定,而 InnoDB 使用行级锁定。在并发访问时,InnoDB 的锁定方式更加精细,可以避免锁定整个表,提高了并发性能。
数据完整性不同:MyISAM 不支持事务和外键约束,而 InnoDB 支持事务和外键约束,可以保证数据的完整性和一致性。
读写性能不同:MyISAM 的读写性能相对较高,适合于读密集型应用;而 InnoDB 的写性能相对较高,适合于写密集型应用。
空间利用率不同:MyISAM 不支持行级别的存储,存储空间利用率较低;而 InnoDB 支持行级别的存储,存储空间利用率更高。
1.4. MySQL 存储引擎选择
在选择 MyISAM 和 InnoDB 引擎时,需要考虑应用场景和需求:
如果应用主要是读操作,可以考虑选择 MyISAM 引擎,以提高读取性能。
如果应用主要是写操作或需要支持事务和外键约束,可以考虑选择 InnoDB 引擎,以保证数据的完整性和一致性。
如果需要高性能和高可用性,可以考虑选择使用 MySQL 集群或使用多个副本实例,并将数据分布在不同的节点上。
总结:MySQL 支持多种存储引擎,MyISAM 和 InnoDB 是其中最常用的两种,它们有不同的特点和优缺点,在选择时需要根据应用场景和需求进行考虑和权衡。
1.5. 指定 MySQL 默认的存储引擎
1.5.1. 全局-配置文件 my.cnf
default-storage-engine=InnoDB
# 设置 MySQL 的默认存储引擎
default-storage-engine=MyISAM
#default-storage-engine=InnoDB1.5.2. 已有表换存储引擎
ALTER TABLE your_table ENGINE = MyISAM;
2. MySQL 主从复制
https://developer.aliyun.com/article/770923 MySQL主从复制读写分离,看这篇就够了!
https://blog.csdn.net/K_520_W/article/details/123763566 mysql主从复制优缺点
做读写分离的原因:数据库写入效率要低于读取效率,一般系统中数据读取频率高于写入频率,单个数据库实例在写入的时候会影响读取性能,这是做读写分离的原因。
MySQL读写分离的基础:实现方式主要基于mysql的主从复制,通过路由的方式使应用对数据库的写请求只在master上进行,读请求在slave上进行。
2.1. MySQL 主从复制的优点和主要用途
2.1.1. 优点
数据分布 (Data distribution )
负载平衡(load balancing)
数据备份(Backups) ,保证数据安全
高可用性和容错行(High availability and failover)
实现读写分离,缓解数据库压力
由于 mysql 实现的异步复制,所以主库和从库数据之间存在一定的差异,在从库执行查询操作需要考虑这些数据的差异,一般只有更新不频繁和对实时性要求不高的数据可以通过从库查询,实行要求高的仍要从主库查询。
2.1.2. 主要用途
读写分离:在开发工作中,有时候会遇见某个sql 语句需要锁表,导致暂时不能使用读的服务,这样就会影响现有业务,使用主从复制,让主库负责写,从库负责读,这样,即使主库出现了锁表的情景,通过读从库也可以保证业务的正常运作。
数据实时备份:当系统中某个节点发生故障时,可以方便的故障切换(主从切换),提高数据安全:因为数据已复制到从服务器,从服务器可以终止复制进程,所以,可以在从服务器上备份而不破坏主服务器相应数据;
高可用(HA):
因为数据库服务器中的数据都是相同的,当Master挂掉后,可以指定一台Slave充当Master继续保证服务的运行,因为数据是一致性的(如果当插入时Master就挂掉,可能不一致,因为同步也需要时间)当然这种配置不是简单的把一台Slave充当Master,毕竟还要考虑后续的Slave的数据同步到Master。
在主服务器上执行写入和更新,在从服务器上向外提供读功能,达到读写分离的效果,也可以动态地调整从服务器的数量,从而调整整个数据库的性能。
在主服务器上生成实时数据,而在从服务器上分析这些数据,从而提高主服务器的性能。
架构扩展:随着系统中业务访问量的增大,如果是单机部署数据库,就会导致I/O访问频率过高。有了主从复制,增加多个数据存储节点,将负载分布在多个从节点上,降低单机磁盘I/O访问的频率,提高单个机器的I/O性能。
2.2. 部署 MySQL
docker 部署,命令为: docker run -p 3306:3306 --name mysql_test -d --restart=always --privileged=true -v /opt/app/mysql/log:/var/log/mysql -v /opt/app/mysql/data:/var/lib/mysql -v /opt/app/mysql/conf/my.cnf:/etc/mysql/my.cnf -e MYSQL_ROOT_PASSWORD=Leon@123 public.ecr.aws/docker/library/mysql:8.0.29
2.3. MySQL 主从复制操作步骤(文件和 pos 形式)
https://cloud.tencent.com/developer/article/1822790 这次终于把MySQL主从复制总结全面了!!!
https://blog.csdn.net/jianghuchuang/article/details/141779089 Mysql8 主从复制&主从切换(超详细)
参考了豆包 AI 的操作步骤。
2.3.1. 配置文件(server-id、开启 binlog)
有关联的 MySQL(例如主从、集群等)设置不同的 server-id;
开启 binlog。
binlog 格式:设置为 ROW,基于行的复制,减少不确定函数如 NOW() 导致的数据不一致问题。
MySQL 5.7.8 及以后的版本,默认的 binlog_format 是 ROW。
STATEMENT:基于语句的复制,将执行的 SQL 语句记录在二进制日志中。这种方式比较简单,但在一些情况下可能会导致复制问题,例如使用非确定性函数(如 NOW()、UUID() 等)时,因为这些函数在主从库上执行的结果可能不同,会导致主从数据不一致。
ROW:基于行的复制,将实际修改的数据行记录在二进制日志中。这种方式可以解决基于语句复制的一些问题,如非确定性函数的问题,但会导致二进制日志文件较大,因为会记录每一行的修改信息。
MIXED:混合模式,根据不同的情况,会选择使用 STATEMENT 或 ROW 模式进行复制。例如,对于非确定性函数,会使用 ROW 模式,而对于一些简单的、不会导致数据不一致的 SQL 语句,会使用 STATEMENT 模式。
额外的,主库可以设置默认存储引擎为 InnoDB,从库可以设置默认存储引擎为 MyISAM。
主 MySQL
[client]
# 设置客户端默认字符集utf8mb4
default-character-set=utf8mb4
[mysql]
# 设置服务器默认字符集为utf8mb4
default-character-set=utf8mb4
[mysqld]
# 配置服务器的服务号,具备日后需要集群做准备
server-id = 1
# 开启MySQL数据库的二进制日志,用于记录用户对数据库的操作SQL语句,具备日后需要集群做准备
log-bin=mysql-bin
# 设置清理超过30天的日志,以免日志堆积造过多成服务器内存爆满。2592000秒等于30天的秒数
binlog_expire_logs_seconds = 2592000
# 解决MySQL8.0版本GROUP BY问题
sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION'
# 允许最大的连接数
max_connections=1000
# 禁用符号链接以防止各种安全风险
symbolic-links=0
# 设置东八区时区
default-time_zone = '+8:00'
# 设置 MySQL 的默认存储引擎
#default-storage-engine=MyISAM
default-storage-engine=InnoDB备 MySQL
[client]
# 设置客户端默认字符集utf8mb4
default-character-set=utf8mb4
[mysql]
# 设置服务器默认字符集为utf8mb4
default-character-set=utf8mb4
[mysqld]
# 配置服务器的服务号,具备日后需要集群做准备
server-id = 2
# 开启MySQL数据库的二进制日志,用于记录用户对数据库的操作SQL语句,具备日后需要集群做准备
log-bin=mysql-bin
# 设置清理超过30天的日志,以免日志堆积造过多成服务器内存爆满。2592000秒等于30天的秒数
binlog_expire_logs_seconds = 2592000
# 解决MySQL8.0版本GROUP BY问题
sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION'
# 允许最大的连接数
max_connections=1000
# 禁用符号链接以防止各种安全风险
symbolic-links=0
# 设置东八区时区
default-time_zone = '+8:00'
# 设置 MySQL 的默认存储引擎
default-storage-engine=MyISAM
#default-storage-engine=InnoDB2.3.2. 主服务器上
创建用于复制的用户
获取主服务器的状态信息:记录下 File 和 Position 的值,这些将在从服务器配置中使用。
-- 创建用户并授予复制从服务器权限
CREATE USER 'slave_user'@'%' IDENTIFIED BY 'Leon@123';
GRANT REPLICATION SLAVE ON *.* TO 'slave_user'@'%';
-- 刷新权限,使修改生效
FLUSH PRIVILEGES;
-- 获取主服务器的状态信息:记录下 File 和 Position 的值,这些将在从服务器配置中使用。
SHOW MASTER STATUS;2.3.3. 从服务器上
配置从服务器的复制
启动从服务器的复制进程,检查从服务器的复制状态:查看 Slave_IO_Running 和 Slave_SQL_Running 的值,如果都是 Yes,则表示主从复制正在正常运行。
看 MySQL 日志
-- 配置从服务器的复制
CHANGE MASTER TO
MASTER_HOST='42.194.239.141',
MASTER_USER='slave_user',
MASTER_PASSWORD='Leon@123',
MASTER_LOG_FILE='mysql-bin.000003', # 替换为主服务器的 File 值
MASTER_LOG_POS=861, # 替换为主服务器的 Position 值
get_master_public_key=1;
-- 启动从服务器的复制进程
START SLAVE;
-- 检查从服务器的复制状态
SHOW SLAVE STATUS;2.3.4. 主从复制怎么设置从库的表的存储引擎?
设置从库的存储引擎配置:修改从库的 my.cnf 配置文件,将默认存储引擎设置为 MyISAM。
使用触发器:在从库上创建触发器,在复制过程中,将新创建的表的存储引擎从 InnoDB 更改为 MyISAM。
2.3.4.1. todo
2.3.4.2. 手动修改已有表的存储引擎
ALTER TABLE your_table ENGINE = MyISAM;
2.4. MySQL 主从复制操作步骤(GTID 形式)(推荐)
GTID(Global Transaction Identifier)是 MySQL 5.6 引入并在 MySQL 8 中进一步完善的一个特性,它为每个在主服务器上提交的事务分配一个唯一的标识符。GTID 的格式通常是 source_id:transaction_id,其中 source_id 是服务器的唯一标识符,transaction_id 是服务器上事务的序号。
2.4.1. GTID 的优势
简化复制管理:使用 GTID 可以更方便地进行主从复制的管理,不需要像传统复制那样关注二进制日志文件和位置,只需要使用 GTID 即可。
提高复制安全性:避免了因复制位置错误而导致的数据不一致或复制失败,因为 GTID 是唯一的,并且可以确保事务在从服务器上只执行一次。
易于故障转移:在故障转移时,可以更容易地确定从服务器需要从哪个事务开始复制,无需手动查找复制位置。
2.4.2. 快速开始
2.4.2.1. 主从配置文件
配置 GTID 复制模式为 ON。
# 配置 GTID 复制模式
gtid_mode = ON
enforce_gtid_consistency = ON2.4.2.2. 主服务器上
创建用于复制的用户
获取主服务器的状态信息:记录下 File 和 Position 的值,这些将在从服务器配置中使用。
-- 创建用户并授予复制从服务器权限
CREATE USER 'slave_user'@'%' IDENTIFIED BY 'Leon@123';
GRANT REPLICATION SLAVE ON *.* TO 'slave_user'@'%';
-- 刷新权限,使修改生效
FLUSH PRIVILEGES;
-- 获取主服务器的状态信息:记录下 File 和 Position 的值,这些将在从服务器配置中使用。
SHOW MASTER STATUS;2.4.2.3. 从服务器上
配置从服务器的复制
启动从服务器的复制进程,检查从服务器的复制状态:查看 Slave_IO_Running 和 Slave_SQL_Running 的值,如果都是 Yes,则表示主从复制正在正常运行。
Slave_IO_Running:应该为 Yes,表示从服务器的 I/O 线程正常运行。
Slave_SQL_Running:应该为 Yes,表示从服务器的 SQL 线程正常运行。
Retrieved_Gtid_Set:显示从服务器已经从主服务器获取的 GTID 集合。
Executed_Gtid_Set:显示从服务器已经执行的 GTID 集合。
看 MySQL 日志
-- 配置从服务器的复制
CHANGE MASTER TO
MASTER_HOST='42.194.239.141',
MASTER_USER='slave_user',
MASTER_PASSWORD='Leon@123',
MASTER_AUTO_POSITION = 1;
-- 启动从服务器的复制进程
START SLAVE;
-- 检查从服务器的复制状态
SHOW SLAVE STATUS;2.5. 断主从
断主从:在从节点执行 STOP SLAVE; 命令即可断主从。
恢复主从:在从节点执行 START SLAVE; 命令启动从服务器的复制进程,然后执行 SHOW SLAVE STATUS; 命令检查从服务器的复制状态。
从节点使用 SHOW SLAVE STATUS; 命令检查主从同步时,需要关注控制台打印结果中的“Slave_IO_Running”以及“Slave_SQL_Running”两个选项,两个选项都为 yes,说明主从同步以及成功启动。
2.6. 相关原理
https://blog.csdn.net/K_520_W/article/details/123763566 mysql主从复制优缺点
https://blog.csdn.net/qq_41786285/article/details/109304126 超详细!MySQL如何实现主从复制和读写分离(原理详解和实操)
https://www.cnblogs.com/shoshana-kong/p/17318124.html 【MySQL】主从复制实现原理详解
2.6.1. 主从复制原理
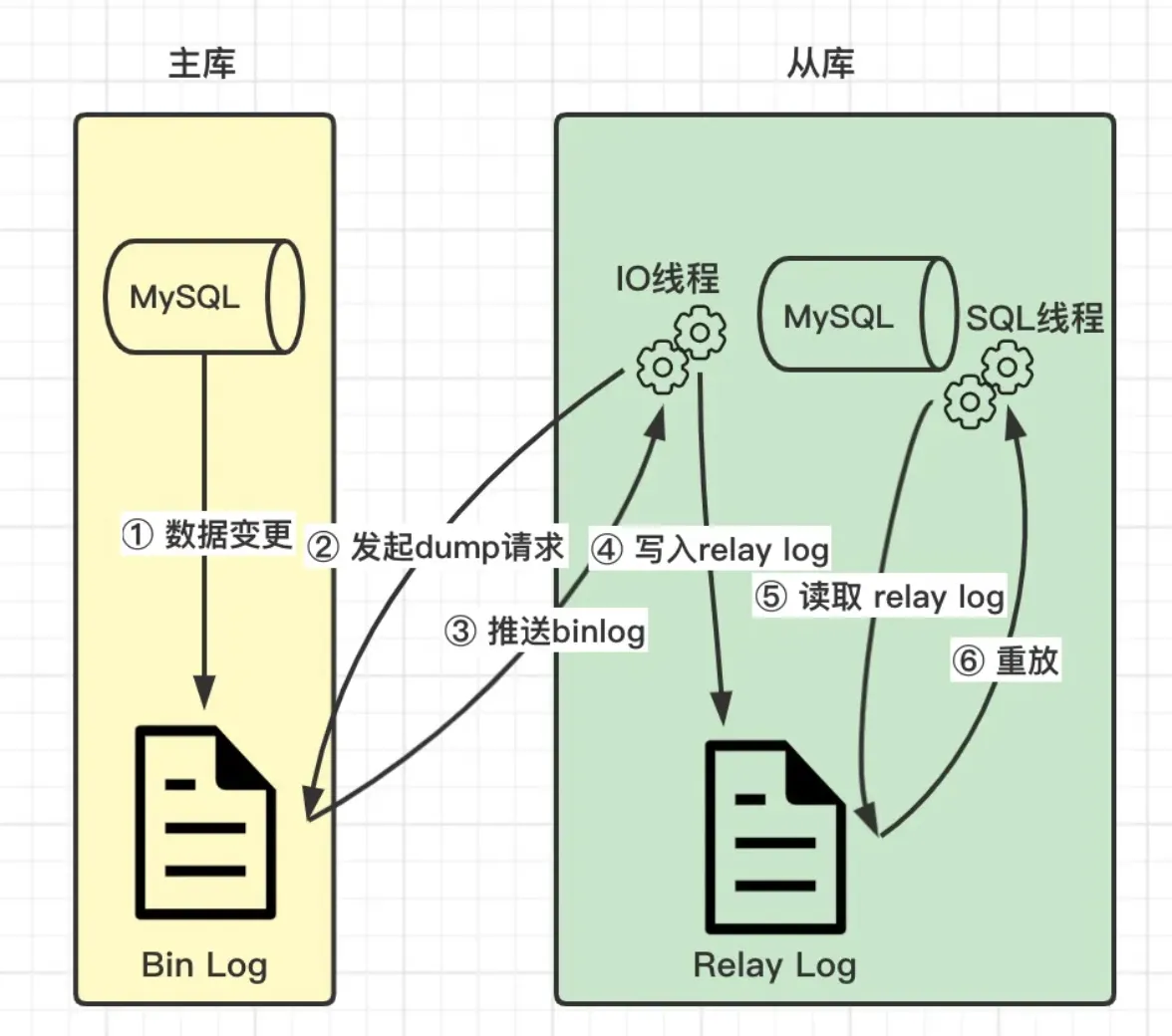
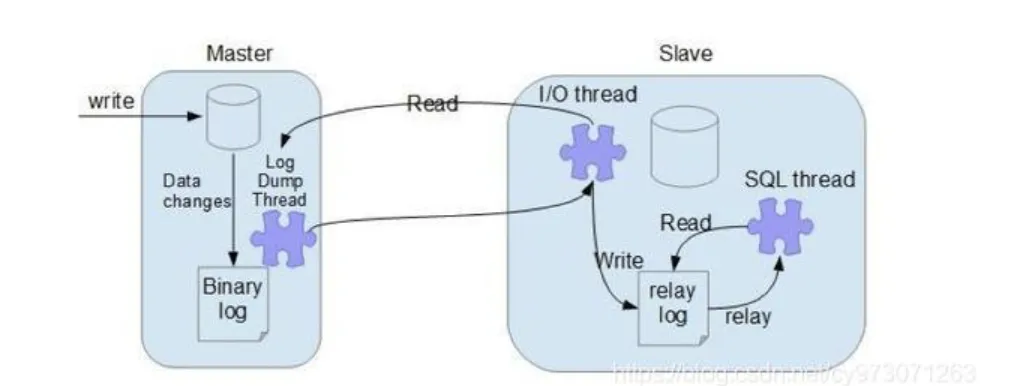
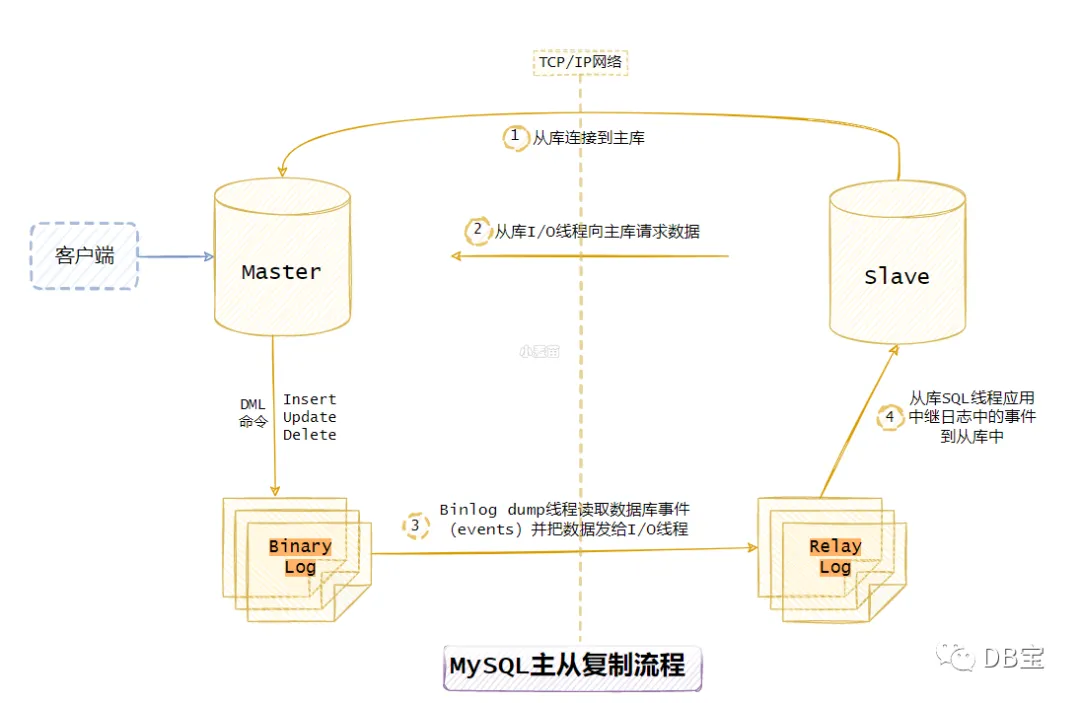
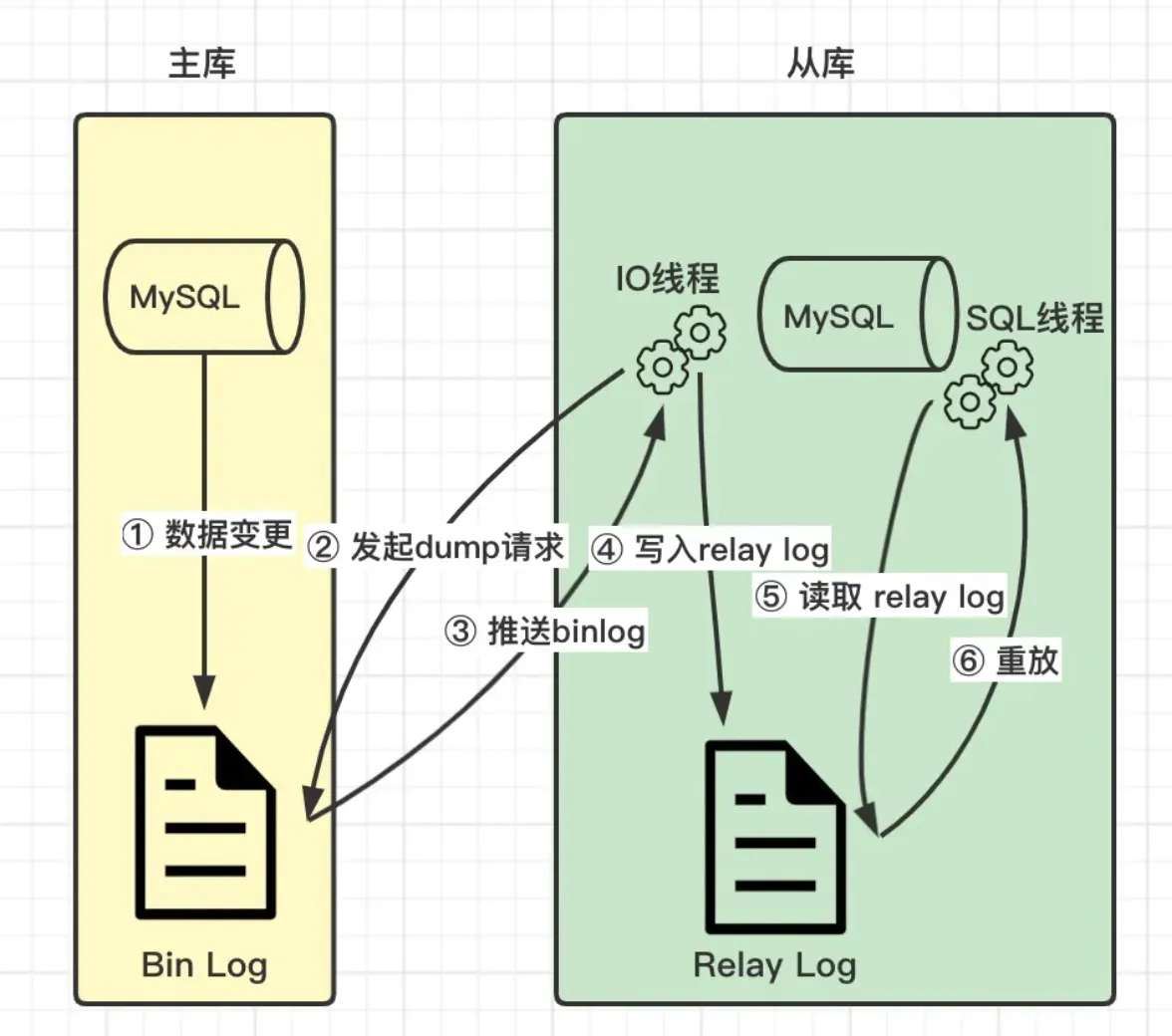
简述:
MySQL 主库将数据变更以二进制格式保存到 BinaryLog 日志文件中。
MySQL 从库开始复制时,会通过 IO 线程发起 dump 请求,等待主库推送 binlog,接收到之后,将该 binlog 写入 relaylog。通过 SQL 现成读取 relaylog,并执行这些 SQL。
详述:
slave端的IO线程连接上master端,并请求从指定binlog日志文件的指定pos节点位置(或者从最开始的日志)开始复制之后的日志内容
master端在接收到来自slave端的IO线程请求后,通知负责复制进程的IO线程,根据slave端IO线程的请求信息,读取指定 binlog日志指定pos节点位置之后的日志信息,然后返回给slave端的IO线程。该返回信息中除了binlog日志所包含的信息之外,还包括本次返回的信息在master端的binlog文件名以及在该binlog日志中的pos节点位置。
slave端的IO线程在接收到master端IO返回的信息后,将接收到的binlog日志内容依次写入到slave端的relaylog文件(mysql-relay-bin.xxxxxx)的最末端,并将读取到的master端的binlog文件名和pos节点位置记录到master- info(该文件存在slave端)文件中,以便在下一次读取的时候能够清楚的告诉master,我需要从哪个binlog文件的哪个pos节点位置开 始,请把此节点以后的日志内容发给我。
slave端的SQL线程在检测到relaylog文件中新增内容后,会马上解析该log文件中的内容。然后还原成在master端真实执行的那些SQL语句,并在自身按顺序依次执行这些SQL语句。这样,实际上就是在master端和slave端执行了同样的SQL语句,所以master端和 slave端的数据是完全一样的。
2.6.2. MySQL 主从复制的模式
MySQL 主从复制默认是异步的模式。MySQL增删改操作会全部记录在bin-log(binary log)中,当slave节点连接master时,会主动从master处获取最新的bin-log文件。并把bin-log存储到本地的relay-log中,然后去执行relay-log的更新内容。
异步模式(mysql async-mode):异步模式如下图所示,这种模式下,主节点不会主动推送bin-log到从节点,主库在执行完客户端提交的事务后会立即将结果返给给客户端,并不关心从库是否已经接收并处理,这样就会有一个问题,主节点如果崩溃掉了,此时主节点上已经提交的事务可能并没有传到从节点上,如果此时,强行将从提升为主,可能导致新主节点上的数据不完整。
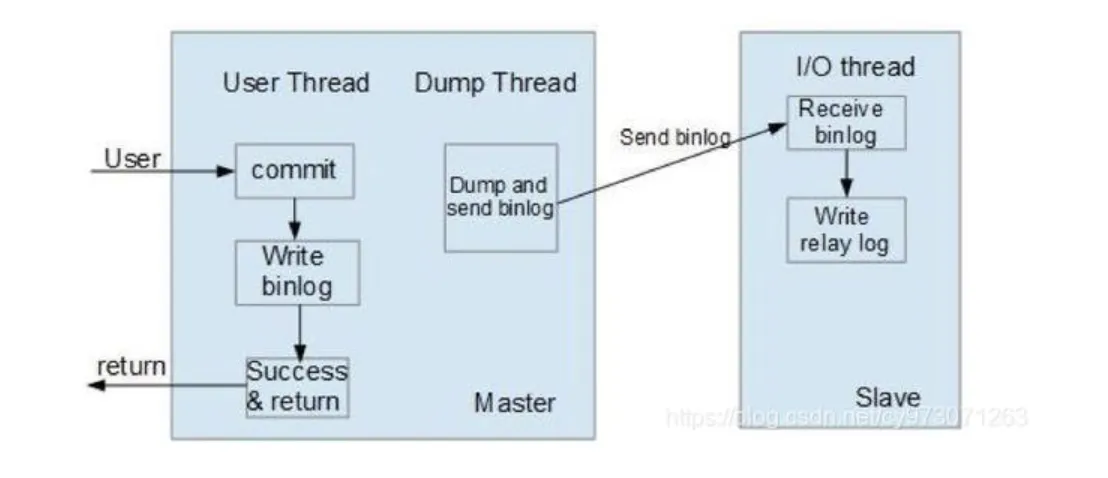
半同步模式(mysql semi-sync):介于异步复制和全同步复制之间,主库在执行完客户端提交的事务后不是立刻返回给客户端,而是等待至少一个从库接收到并写到relay-log中才返回成功信息给客户端(只能保证主库的bin-log至少传输到了一个从节点上,但并不能保证从节点将此事务执行更新到db中),否则需要等待直到超时时间然后切换成异步模式再提交。相对于异步复制,半同步复制提高了数据的安全性,一定程度的保证了数据能成功备份到从库,同时它也造成了一定程度的延迟,但是比全同步模式延迟要低,这个延迟最少是一个TCP/IP往返的时间。所以,半同步复制最好在低延时的网络中使用。如下图所示:
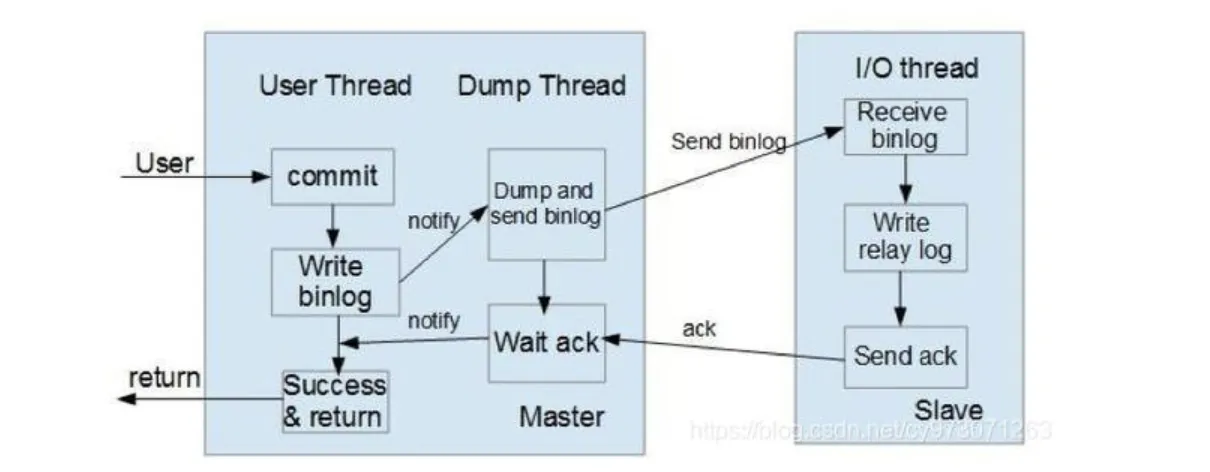
半同步模式不是mysql内置的,从mysql 5.5开始集成,需要master 和slave 安装插件开启半同步模式。
全同步模式:指当主库执行完一个事务,然后所有的从库都复制了该事务并成功执行完才返回成功信息给客户端。因为需要等待所有从库执行完该事务才能返回成功信息,所以全同步复制的性能必然会收到严重的影响。
异步模式,全同步模式,半同步模式的对比图:

2.6.3. GTID 复制模式
参考上文。
2.6.4. 多线程复制
3. MySQL 读写分离
https://developer.aliyun.com/article/770923 MySQL主从复制读写分离,看这篇就够了!
做读写分离的原因:数据库写入效率要低于读取效率,一般系统中数据读取频率高于写入频率,单个数据库实例在写入的时候会影响读取性能,这是做读写分离的原因。
MySQL读写分离的基础:实现方式主要基于mysql的主从复制,通过路由的方式使应用对数据库的写请求只在master上进行,读请求在slave上进行。
3.1. 通过 Apache ShardingSphere-JDBC 实现
4. MySQL 双主互备(VIP 高可用)
https://blog.csdn.net/investor_/article/details/135318532 基于双vip的GTID的半同步主从复制MySQL高可用集群
双主互备就是要保持两个数据库的状态自动同步,对任何一个数据库的操作都自动应用到另外一个数据库,始终保持两个数据库数据一致,这样做的意义是既提高了数据库的容灾性,又可以做负载均衡,可以将请求分摊到其中任何一台上,提高网站吞吐量。
在服务器 A 上配置指向服务器 B 的复制,在服务器 B 上配置指向服务器 A 的复制。然后通过 VIP 实现高可用。
优点:热备、高可用。

5. MySQL 应用层代理-ShardingSphere
6. MySQL 中间件代理-Mycat 简单使用
不要用,从入门到放弃。连个读写分离负载均衡都做不好。
7. MySQL 分库(手动分)
略
8. MySQL 分表(手动分)
https://tech.meituan.com/2016/11/18/dianping-order-db-sharding.html 大众点评订单系统分库分表实践
https://www.elibaron.com/db/mysql/mysql-x-sharding-detail.html MySQL - 分表分库详解
略
9. MySQL 分区(PARTITION)
https://cloud.tencent.com/developer/article/2420277 MySQL分区表:万字详解与实践指南
https://www.cnblogs.com/leepandar/p/18542625 Mysql大表处理方案:分区详解
常见的使用方式,是建表时指定分区,例如按日、月、年分区,然后使用时通过指定时间范围,MySQL 会只在对应分区操作,减少了不必要的扫描,效率高。
在生产环境,不同的分区建议分开存放在不同磁盘存储上,提高磁盘的I/O。大致操作为先用 CREATE TABLESPACE 命令创建不同磁盘的表空间,然后创建分区时指定表空间。

